

För att din webbplats ska kunna synas på Google måste sökmotorn hitta ditt innehåll, läsa av det och förstå det. Ovanpå detta är det viktigt att sajten är användarvänlig, oavsett om den besöks via en dator, mobil eller surfplatta.
Teknisk SEO är en samling metoder och aktiviteter som optimerar din webbplats mot detta och inkluderar bland annat:
- Crawling och indexering: Se till att Google hittar alla dina viktiga sidor och indexerar dem (lägger till innehållet i sin databas “Google Index”)
- Hastighet: Se till att webbplatsen laddar snabbt
- Mobilvänlighet: Se till sajten är användarvänlig på mobiltelefoner
- Strukturerad data – Applicera strukturerad data så att Google bättre förstår ditt innehåll
Man kan säga att teknisk SEO är förutsättningen för att dina övriga SEO-projekt ska kunna bära frukt. Oavsett hur bra innehåll du har, kommer din webbplats aldrig att nå toppen av Google om du inte har en solid teknisk grund.
I den här guiden kommer vi gå igenom de olika områdena och vad du kan göra för att få alla bitarna på plats.
Hur hittar Google innehåll?
För att Google ska kunna ta del av allt innehåll som finns på webben använder de sig av ett program (web crawler) som kallas för Googlebot.
Googlebot letar sig igenom (crawlar) allt innehåll den kommer över och kopierar det till en massiv databas – Google Index.
När någon utför en sökning på Google hämtas svaren från indexet och presenteras i Googles sökresultat.

Crawling
Googlebot crawlar webben genom att besöka och läsa av sidor för att sedan klicka sig vidare via de länkar som den stöter på. På så vis kartlägger den internet, relationerna mellan sidor på webblatser och hur de relaterar till andra, externa sajter.
Det är viktigt att se till att Googlebot kommer åt alla de sidor du vill att användare ska hitta, när de gör sökningar på Google. För att möjliggöra detta behöver du skapa interna länkar mellan sidorna, mer om det nedan.
Om din webbplats är helt ny behöver du först av allt introducera din webbplats för crawlern.
Så presenterar du din webbplats för Googlebot
För att Googlebot ska kunna crawla din webbplats behöver den hitta till sajten, vilket den kan göra på tre sätt:
- Du skickar in en sitemap till Google
- Du ber Google indexera din webbplats
- En annan webbplats som Googlebot crawlar länkar till din webbplats
Du kan inte tvinga någon att länka till dig, så de säkraste (och enklaste) sätten är att du laddar upp en sitemap och/eller ber Google att indexera din webbplats. Detta gör du med hjälp av Google Search Console (GSC) – ett gratis verktyg som du kopplar till din webbplats.

Source: Google Search Consoles start-sida
Ladda upp sitemap i GSC
En sitemap är en kartläggning av de sidor som finns på din webbplats och som du vill att Googlebot ska besöka. I praktiken är det en lång lista av URL:er som Google kan läsa av.
De flesta CMS kan generera sitemaps automatiskt, med rätt tillägg eller inställningar.

Så här ser Klikkos sitemap ut, genererad av Yoast SEO
Du kanske redan har en sitemap, då hittar du den oftast under:
dinsajt.se/sitemap.xm
dinsajt.se/sitemap_index.xml
Du kan också titta i din robots.txt-fil, där finns sitemap ofta med. Robots.txt hittar du under:
dinsajt.se/robots.txt

Om du inte hittat sitemapen än kan du testa att använda dig av Google Search Operators. Skriv in följande rad i webbrowsern:
”site:dinsajt.se filetype:xml”

Om du fortfarande inte hittat din sitemap kan du se dokumentationen från ditt CMS var sitemaps lagras.
När du hittat din sitemap laddar du upp den via GSC genom att klicka på “Sitemaps/Webbplatskartor” i sidomenyn:

Därefter klistrar du in adressen för din sitemap och klickar på “submit/skicka in”

Det kan ta några dagar innan Google processar och accepterar sitemapen. När det väl är färdigt kommer verktyget att ge insikt i vilka sidor Google hittat och framför allt, vilka den valt att indexera (eller inte).
Be om indexering i GSC
Via URL Inspection tool i GSC kan du be Google att indexera specifika URL:er, så knappa in din hemsida här:

Därefter kan du be Google att indexera webbsidan:

Google kommer att besöka webbsidan och, om du har en fungerande intern länkstruktur, crawla resten av sajten och förhoppningsvis indexera innehållet. Vi återkommer till indexering senare.
Webbplatsstruktur och interna länkar
Google tycker om lättnavigerade webbplatser, precis som vilken besökare som helst. Helst ska varje sida kunna nås via så få klick som möjligt från startsidan. Det underlättas med en platt och logisk webbplatsstruktur.
En bra lösning är att skapa en tydlig kategoristruktur med huvudkategorier som länkar till relevanta underkategorier, vilka i sin tur länkar till produkter och tjänster. Enklast är att illustrera det med ett exempel från en hypotetisk webbshop som säljer hemelektronik:

Med denna struktur blir det enkelt både för en besökare och Google att göra en logisk resa från startsidan till produkt genom att klicka på
- Huvudkategori (Mobiltelefoner)
- Underkategori (Märke)
- Produkt (Specifik mobiltelefon)
Alla produkter nås via tre klick från startsidan, vilket är ett bra klickdjup. Du vill inte gömma sidor för djupt på din webbplats, det gillar vare sig Google eller användare.
OBS! Det kan ofta vara relevant att börja visa produkter redan under huvudkategorin, alla mobiltelefoner i mobiltelefon-kategorin ovan, exempelvis. Se nedan hur det kan se ut i verkligheten:

Exempel på på bra kategoristruktur från prisjakt.nu
Med en tydlig struktur och hierarki blir det enkelt att skapa nya sidor och placera dem rätt. Det minimerar också risken att du skapar orphaned pages (föräldralösa sidor), alltså sidor som inte har någon länk till dem. Om sidor inte har länkar till dem finns det risk att de inte indexeras, även om de finns med i din sitemap. Och även om de indexeras är det en dålig rankingsignal för google att de inte har några internlänkar.
Så skapar du en bra struktur
Visualisera dina sidor, hur de hänger samman och skapa därefter en kategorisering. Detta gäller både för e-handlare och tjänsteutövare. Till exempel skulle en advokatbyrå kunna ha affärsjuridik och privatjuridik som huvudkategorier. Därunder skulle de sedan kunna samla:
- Affärsjuridik – Arbetsrätt, Avtalsrätt, kommersiella tvister med mera
- Privatjuridik – Familjerätt, Migrationsrätt, konsumenttvister med mera
Under familjerätt skulle än mer specifika tjänster kunna finnas som fullmakt, skilsmässa, vårdnadstvist med mera.
För att hjälpa besökarna med informativa sidor kan de också har en blogg, vilken får leva för sig själv. Då hade den slutliga strukturen sett ut så här:

Alla sidor nås via maximalt tre klick från hemsidan och strukturen är användarvänlig.
Genom att skapa den här typen av arkitektur för webbplatsen kommer Google lätt att kunna crawla och förstå relationerna mellan sidorna.
När du har struktur och sitemap på plats är det dags att förstå om och hur Google indexerar din webbplats.
Indexering
Indexering är metoden som Google använder för att lagra och organisera de sidor som den crawlat. Men, bara för att Google crawlar dina sidor är det inte garanterat att de läggs till i indexet.
Du kan kontrollera om dina sidor indexeras på olika sätt:
1. Google Site Operator
Öppna en browser och skriv följande i sökfältet:
site:dinwebbplats.se

Det kommer att ge dig en ungefärlig lista över alla URL:er som Google har indexerat från din sajt.
Du kan också se om en specifik URL är indexerad genom att skriva in den efter site-operatorn:
site:dinwebbplats.se/specifik-url

2. URL Inspection Tool
I Google Search Console kan du knappa in den fullständiga URL:en du vill kontrollera i “URL Inspection Tool”, så berättar verktyget om sidan är indexerad, eller inte.

Sidan är indexerad

Sidan är inte indexerad
För sidor som inte är indexerade kan verktyget också ge dig information om varför. Det är värdefullt när du felsöker och åtgärdar problem med indexeringen:

Orsak till att sidan inte är indexerad
I Google Search Console hittar du också funktionen “Pages” under “Indexing”. Här kan du se alla sidor som Google har hittat på din webbplats och om de är indexerade eller inte.

Åtgärda problem med indexering
Det är ett detektivarbete att reda ut varför sidor inte indexeras och lyckligtvis finns det bra verktyg för att hjälpa dig:
- Google Search Console (GSC) – Gratis för alla webbplatsägare
- Externa verktyg – Tredjepartsverktyg som crawlar din webbplats och identifierar problem. Det mest välkända (med god anledning) är Screaming Frog
Hitta indexeringsproblem med GSC
“Indexing” i Google Search Console ger rapporter över vilka sidor på din webbplats som Google känner till och vilka som är indexerade, eller inte.
Under grafen i ”Pages” som vi nämnde ovan ser du hur många sidor som Google känner till och deras indexeringsstatus. Om du scrollar ner under denna hittar du en lista över vilka problem du har med indexering och vilka sidor som drabbas av vilket problem:

Inte alla orsaker är egentliga problem; redirectade (omdirigerade), canonicalised (kanonikaliserade) eller “noindex”-sidor kan vara medvetna och korrekta.
Det är viktigt att gå in på olika “reasons” för att se så att det är i ordning och åtgärda de fel du hittar. Det kan vara allt från felaktiga redirects, 404-sidor som har inlänkar eller sidor som crawlats, men inte indexerats.
Andra analysverktyg
Efter att du åtgärdat alla fel du hittat i GSC är det en bra idé att köra sajten genom ett externt verktyg för att täppa till alla luckor. Det finns en hel del bra alternativ på marknaden. Bland annat Ahrefs och SEMRush är verktyg som gör tekniska-, men även sökord- och backlinks-analyser.
Vi rekommenderar främst Screaming Frog, vilket är ett verktyg helt dedikerat till att hitta tekniska fel och möjligheter på din webbplats. Skriv in din hemsida i verktyget så får du en detaljerad lista över problem och hur du löser dem. Det är ovärderligt om du arbetar med teknisk SEO.

Screaming Frog (upptäckta problem markerade i rött)
Det är speciellt problemen som märkts ut med High eller Medium priority du bör rikta in dig på. Åtgärda dessa snarast.
Vanliga indexeringsproblem och hur du löser dem
Det finns många möjliga anledningar att Google inte väljer att indexera sidor på din webbplats. Vi kommer inte att kunna gå igenom alla, men några vanliga problem är:
- 404-sidor
- Felaktiga redirects
- Felaktiga noindex-taggar
- Blockerad av robots.txt
- Duplicerat innehåll
404 – Not found
404 är en felkod som genereras när en länk går till en sida som inte existerar. Det är varken bra för användare, eller Google. Det kan lösas på olika sätt, beroende på sammanhang, bland annat:
- Felskriven – Om URL:en i länken/länkarna till 404-sidan är felskriven, rätta till den på alla ställen.
- Borttagen av misstag – Om sidan är borttagen av misstag, återupprätta den.
- Flyttad – Om sidan har fått en ny adress, exempelvis om exempelsajt.se/topp-10-produkter/ är flyttad till exempelsajt.se/guider/topp-10-produkter/, sätt en redirect på den gamla sidan till den nya. Peka om länkar till den gamla sidan så de pekar mot den nya.
- Permanent borttagen – Om sidan är permanent borttagen medvetet, fundera på om det kan vara relevant att redirecta sidan till en annan, relevant sida. Se då också till att peka om länkarna mot den nya sidan istället. Alternativt, ta bort alla länkar som pekar till den felaktiga sidan från webbplatsen och sitemap.
Bonus: 404-sidor kommer dina besökare att råka ut för, vare sig du vill det eller inte. Kanske de skriver in en felaktig adress när de ska besöka en av dina sidor. Då kan det vara bra att ha en så trevlig och användarvänlig upplevelse som möjligt.

Source: Exempel på en fyndig 404-sida från marvel.com
Du kan designa din egen 404-sida, där det kan vara en bra idé att inkludera länkar till populära kategorier och produkter, exempelvis.
Felaktiga redirects
Redirect är ett direktiv som omdirigerar en besökare eller bot från en sida till en annan. Det används ofta när innehåll flyttar från en URL till en ny. Problem med redirects kan uppstå av olika orsaker, som i slutändan leder till att Google inte indexerar den slutgiltiga mål-sidan:
- För långa redirect-kedjor – En URL redirectas till en ny, som i sin tur redirectar vidare till en annan URL, som redirectar till en annan och så fortsätter det. Om kedjan blir för lång kommer Google till slut att ge upp att följa den. Lösningen är att helt enkelt minimera antalet redirects, helst ska alla länkar peka till sidor som INTE är redirectade.
- Redirect-Loopar – En URL redirectas till en URL, eller kedja av redirects som i slutändan redirectas tillbaka till den ursprungliga URL-en. Det skapar en oändlig loop som slutar i ett felmeddelande för besökare eller boten. Lösningen är att redirecta samtliga URL-er till den önskade sidan och se till att alla länkar på sajten pekar mot densamma.
- Redirect-kedja med en felaktig eller tom URL – Om en redirectkedja innehåller en felaktig eller tom URL, vilket gör den oanvändbar. Korrigera den felaktiga URL-en, men se också till att peka alla redirects mot rätt URL och se till att alla länkar på sajten pekar mot den.

Source: Screaming Frog identifierar redirect-kedjor och -loopar
Felaktiga noindex-taggar
Noindex är ett direktiv för Google att inte indexera en sida. Ett vanligt misstag är att det lagts till noindex-taggar på sidor som egentligen ska indexeras. Ta helt enkelt bort noindex-taggen.

Så ser noindex-taggen ut i kod
Blockerad av robots.txt
Ibland råkar webbansvariga blocka kritiska sidor eller resurser i sin robots.txt-fil. Se över instruktionerna i filen så de inte blockerar Googlebot från de sidor som du vill ha indexerade.
Blockerad av robots.txt
Ibland råkar webbansvariga blocka kritiska sidor eller resurser i sin robots.txt-fil. Se över instruktionerna i filen så de inte blockerar Googlebot från de sidor som du vill ha indexerade.
Duplicerat innehåll
Med duplicerat innehåll menas att du på din sajt har sidor som är nästan- eller helt identiska med varandra. Eller ännu värre, om du har kopierat innehåll rakt av från en extern webbplats.
Duplicerat innehåll kan bero på olika saker, men oavsett kan det få oönskade konsekvenser om det inte tas om hand korrekt:
- Google får svårt att avgöra vilket innehåll som ska indexeras. Det kan leda till att olika sidor byter av varandra i sökresultaten för samma sökning.
- Google kan välja att ranka ned sidor eller till och med vägra att indexera sidor med duplicerat innehåll.
Det finns olika sätt att identifiera om du har duplicerat innehåll.
- I GSC kan du se varningar när Google hittat duplicerat innehåll på din webbplats och hur de förhåller sig till dem. Du hittar dem under indexing – pages i rapporten “Why pages aren’t indexed”. Leta efter:
- Duplicate without user-selected canonical
- Duplicate, Google chose different canonical than user
- Duplicate, submitted URL not selected as canonical
- Det finns flera verktyg som kan identifiera duplicerat innehåll, bland annat Ahrefs, SEMRush och Screaming Frog.

Source: Identifiera duplicerat innehåll i Screaming Frog
Om du märker att du har duplicerat innehåll finns det olika sätt att åtgärda problemen: Redirect, Noindex eller Canonical. Vilken lösning som passar bäst beror på kontexten.
- Redirects kan vara användbara om du märker att du av misstag skapat en dubblett av en sida och som inte tillför något värde där den finns. Sätt upp en redirect och rikta om alla länkar som pekar mot dubbletten till originalet.
- Noindex kan vara en lösning för duplicerat innehåll som är användbart för besökare, exempelvis alla tag- och kategorisidor som genereras av ditt CMS (vanligt i WordPress). De har inget unikt innehåll, men används för navigation.
- Canonical är ett direktiv för Google som anger en annan URL som den huvudsakliga versionen av sidan. Det kan exempelvis användas för i närmast identiska produktsidor på en e-commerce-sajt.Exempel: Om du har en sida för en klänning och fyra länkade sidor för olika färgvarianter kan färg-sidorna med fördel ha canonical-taggar som pekar mot huvudsidan.
Best practice efter åtgärder
Efter att du genomfört en åtgärd på din webbplats är det bra om du verifierar att den fungerar som den ska. Screaming Frog passar utmärkt till detta. Om du redan gjort en crawl av din sajt i verktyget kan du jämföra den första crawlen med den nya.
Därefter går du in i Google Search Console, öppnar “Pages” och klickar på problemet du åtgärdar och sedan “Validate Fix”

Not: Det kan dröja ett tag innan Google verifierar om åtgärden gått igenom.
Du har nu, om du följt guiden, åstadkommit följande:
- En sajtstruktur som är platt och länkar till alla de sidor som du vill att Google och användare ska se.
- Laddat upp din sitemap via Google Search Console.
- Korrigerat fel som hindrar Google från att indexera dina sidor korrekt.
Grattis! Du har precis skapat en bra grund för Google att crawla och indexera dina sidor. Det är dags att vi tar en vidare titt på nästa tekniska aspekt, som Google värderar högt: hastigheten.
Hastighet och SEO
Hastighet, eller PageSpeed, är en direkt rankingfaktor som påverkar din webbplats placering i sökresultaten. Precis som med alla andra rankingfaktorer vet vi dock inte hur mycket inflytande det har.
Statistiken att ju långsammare en webbsida laddar, desto högre risk är det att en användare tappar tålamodet och “bouncear”. Det betyder att de lämnar sidan utan att ha interagerat med den (och i värsta fall går de till en konkurrent). Google noterar hur användare beter sig och om de ser ett mönster att besökare snabbt lämnar din webbsida riskerar den att tappa positioner i sökresultaten.
Fakta: Risken att få en bounce ökar med hela 32% om sidan går från en laddtid på 1 sekund till 3 sekunder.
Hur optimerar man sin PageSpeed?
Det första du bör göra är att testa din webbplats i Googles PageSpeed Insights, vilket är ett gratis verktyg från Google. Där kan du analysera en URL i taget och verktyget visar dig din nuvarande status och en mängd förbättringsområden inom både Hastighet, UX och SEO.

Det ger dig också tips på vad och hur du kan göra för att förbättra olika delar av webbsidan.

Det finns en mängd olika aspekter av en webbplats som påverkar laddtider och vi kan inte lista dem alla här. Vanliga metoder för att snabba upp din webbplats inkluderar bland annat:
Komprimera filer
Använd komprimeringsprogram/format som gzip för att komprimera CSS, HTML, och JavaScript-filer som är större än 150 bytes. Men använd inte detta för bilder.
Försök att minimera bilder (utan att kompromissa på kvaliteten) med hjälp av program som PhotoShop eller gratistjänster som TinyPNG.

TinyPNG
Olika bildformat är bra för olika typer av bilder:
JPG – Bäst för fotografier
PNG – Bäst för grafik, designelement och logotyper
Reducera Redirects
Varje redirect saktar ner laddtiden för besökaren, så undvik så långt som möjligt onödiga redirects och speciellt långa redirect-kedjor (som vi pratat om ovan).
Använd ett CDN
CDN, eller Content Delivery Networks, är en grupp servrar distribuerade över ett större geografiskt område. De lagrar en cachead version av din webbplats för att ge en snabbare och mer pålitlig tillgång till sajten för folk närmare CDN-servern.
Minifiera CSS, JavaScript, och HTML
Optimera koden, exempelvis genom att ta bort onödiga:
- Mellanslag
- Kommatecken och andra överflödiga tecken
- Kommentarer
- Oanvänd kod
Reducera HTTP requests
Ju fler filer en browser behöver begära från servern som hostar din webbplats, desto långsammare blir laddningstiden. Det kan handla om att du har många bilder, inbäddade videos, onödiga plugins med mera. Gå igenom dina sidor och se över om alla resurser verkligen bidrar till upplevelsen och om du har plugins installerade som är överflödiga.
Du kan också använda dig av lazy loading, vilket innebär att innehåll inte laddas förrän användaren scrollat till området på sidan där innehållet finns.
Externa verktyg
Förutom PageSpeed insights finns det flera verktyg som analyserar webbplatshastigheter på ett djupare plan, bland annat GTMetrix och WebPageTest
Mobilvänlighet
Hösten 2016 påbörjade Google initiativet Mobile First Indexing, vilket innebär att de använder mobilversionen av en sajt för att crawla och indexera den. Sju år senare, 2023, blev de färdiga med implementeringen och numera används aldrig desktop-versionen av Googlebot.

Källa: Google
Varför?
För att majoriteten av jordens befolkning använder mobilen när de konsumerar information på internet.
Vad innebär det?
I praktiken innebär det att det inte spelar någon roll om din webbplats ser fantastisk ut på en dator, men inte fungerar på mobilen. Googlebot bryr sig bara om mobilversionen.
Dessutom kommer du att tappa möjligheten att tillfredsställa och konvertera användare som besöker dig från sina mobiltelefoner.
Hur optimerar du för mobile first?
Du behöver framför allt se till att innehållet på mobil och desktop är detsamma. Den vanligaste lösningen för detta är att implementera responsiv design på webbplatsen, vilket majoriteten av webbplatserna har idag.
Vad många dock missar är att använda mobil-versionen som utgångspunkt när de utvecklar webbplatser och nya sidor. Med största sannolikhet är det mobilversionen av din sida som majoriteten av användarna kommer att interagera med.
Även om sidor designas på desktop måste man hela tiden se till att först och främst utvärdera hur resultatet kommer att se ut i mobilen. Det finns olika verktyg du kan använda dig av för att se hur en webbplats ser ut i olika enhetstyper, exempelvis browserstack.
Ett gratis och enkelt sätt att få en snabb blick över hur din webbplats ser ut i mobil är att använda sig av Google Chromes “Inspektera”-funktion (högerklicka någonstans på webbplatsen):
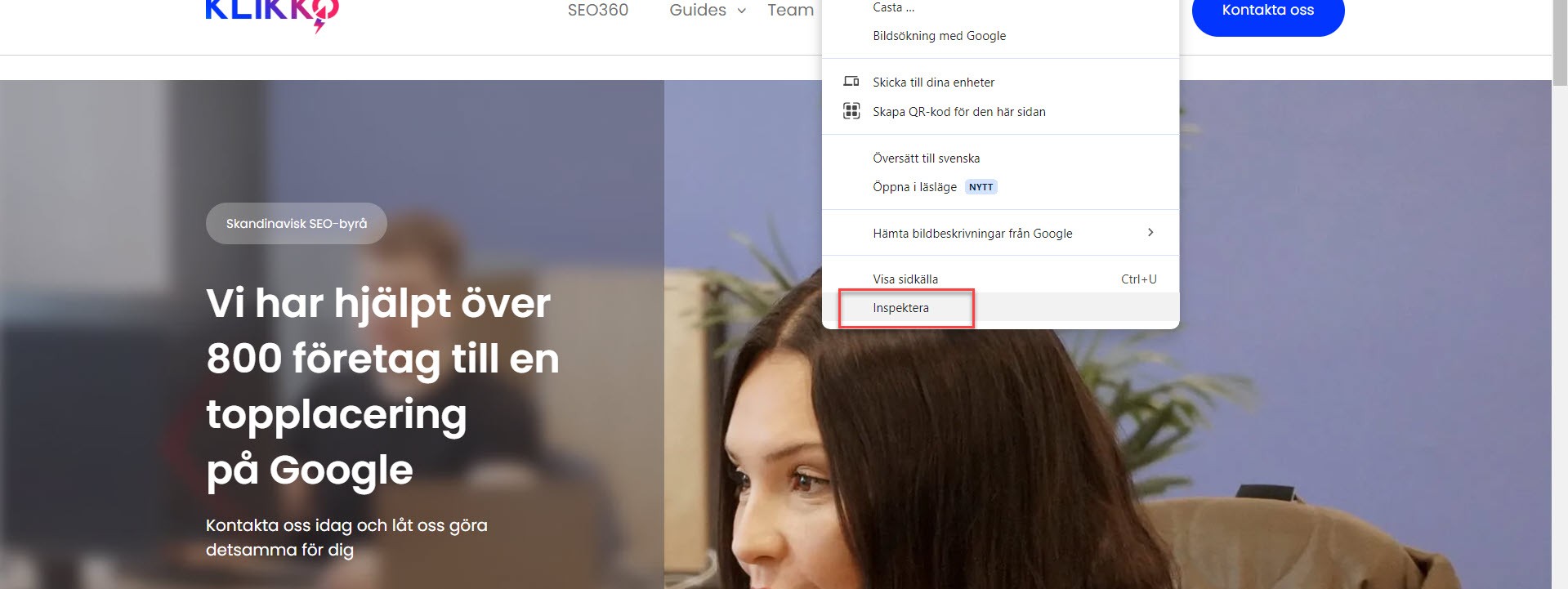
Därefter växlar du till mobilvy här:

Sedan kan du se hur webbsidan ser ut i mobil och du kan byta simulerad mobil-modell här:

För mobilanvändare är en snabb webbplats extra viktig eftersom de ofta är beroende av sin mobiluppkoppling när de surfar. Det kan vara särskilt viktigt om din målgrupp befinner sig i områden med dålig uppkoppling/täckning.
Använd Googles PageSpeed Insights eller Google Lighthouse för att se hur snabbt din webbplats laddar i mobil och rekommenderade åtgärder för att förbättra hastigheten:

Google PageSpeed Insights
Som vi nämnde ovan kan du också använda dig av andra externa verktyg som GTMetrix.
Strukturerad data
Avslutningsvis kommer vi att prata om strukturerad data, eller structured data som det heter på engelska. Strukturerad data är ett dataset som organiseras och struktureras på ett specifikt sätt på en webbsida.
I en SEO-kontext är det data som presenteras i ett standardiserat format för att leverera information om innehållet på en webbsida till sökmotorer. Det kan vara allt ifrån ingredienser och tillagningstid för recept, öppettider för butiker, pris och betyg för produkter, med mera.
Varför är det viktigt?
Strukturerad data hjälper sökmotorer att förstå innehållet på webbsidor så att de i slutändan kan skapa rikare och mer personliga sökresultat, så kallade “Rich Results”. Det är hjälpsamt för användare och ger webbplatser som implementerat strukturerad data ökad chans att få besökare. Se exempel nedan på sökresultat som berikats med hjälp av strukturerad data:

Rich Results för sökningen “iphone 15 pris”
Hur implementerar man strukturerad data?
För att kommunicera strukturerad data till en browser behövs ett vokabulär (ord som ger mening till mottagaren) och ett format (regler för hur orden används för att förmedla budskapet).
Det vanligaste vokabuläret, universellt för de största sökmotorerna, är schema.org. Du kan hitta mer information om det på webbplatsen: https://schema.org/
Den vanligaste syntaxen, som Google också rekommenderar, är JSON-LD.
Strukturerad data implementeras direkt i koden på webbsidan och det finns en mängd olika typer av Rich Results du kan optimera för. Här kan du se Googles egna dokumentation kring de olika varianterna.
Efter implementation bör du testa din sida i Rich Results Test för att se att det fungerar som det ska.

Avslutande ord
När du jobbar med teknisk SEO är det viktigt att förstå att arbetet aldrig riktigt tar slut. Det digitala landskapet utvecklas ständigt. Google lanserar kontinuerligt nya funktioner och best practices som det är viktigt att hålla sig uppdaterad kring.
En bra idé är att följa Googles egna blog kring hur sökmotorn utvecklas eller, våra personliga favoriter Search Engine Journal och Searchengineland
Och såklart bör du signa upp för vårt nyhetsbrev så levererar vi dig de senaste nyheterna, på svenska.
Om du känner att du vill ha hjälp med din tekniska SEO är det bara att du kontaktar oss så får du en kostnadsfri, grundläggande analys.
