En web crawler, som även kan kallas för spider eller bot, är ett automatiserat script eller program som systematiskt surfar internet för att indexera webbsidors innehåll. Crawlers är en fundamental del av sökmotorer, där de används för att samla in data som sökmotorerna sedan använder för att ranka webbsidor baserat på relevans och auktoritet.
Funktionalitet
Web crawlerns huvudfunktion är att besöka och läsa av webbsidor för att sedan skicka tillbaka denna information till sökmotorns databas. Denna process startar typiskt med en lista över webbadresser (URL:er) att besöka, känd som seeds. Crawler används för att upptäcka och följa länkar på dessa sidor och lägger sedan till de nya URL:erna till listan över sidor att besöka.
En av de vanligaste web crawlers man stöter på inom SEO är Googlebot, som crawlar webben för att fylla på Googles index:
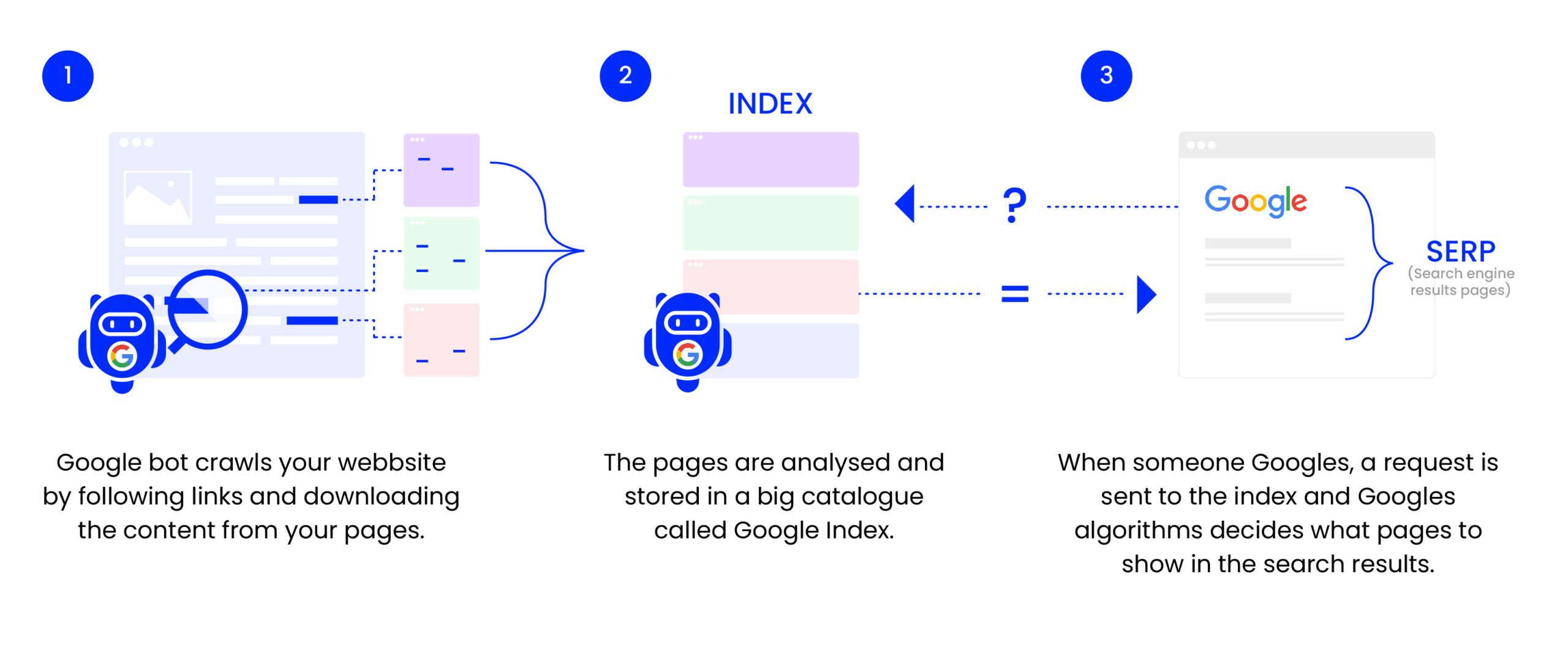
Användning i SEO
För en teknisk SEO-specialist är förståelsen för hur web crawlers fungerar avgörande. Genom att optimera en webbplats struktur, interna länkar och meta-tags (såsom title och description) kan en SEO-expert förenkla arbetet för en crawler, vilket i sin tur ökar sannolikheten att sidan indexeras korrekt och rankas väl. Användning av robot.txt-filer kan styra och effektivisera en crawlers beteende, genom att indikera vilka delar av en webbplats som ska besökas eller ignoreras.
Utmaningar
Crawlers navigerar i en ständigt föränderlig webbmiljö och kan stöta på problem såsom crawl traps (där en crawler fastnar i en oändlig loop av URL:er) och duplicate content (där samma innehåll finns tillgänglig på flera URL:er). SEO-experter bör se över och konfigurera sina webbsidor för att minimera dessa problem, vilket bidrar till en mer effektiv crawlprocess och, i slutändan, bättre SEO-resultat.
Best Practices
- Använd en tydlig och logisk URL-struktur.
- Säkerställ att webbplatsen har en XML-sitemap som hjälper crawlers att förstå sidans struktur.
- Optimera laddningstider eftersom crawlers har en begränsad budget för hur mycket tid de tillbringar på en webbplats (crawl budget).
- Tillämpa korrekt användning av robot.txt för att guida crawlers till relevant innehåll.
- Använd korrekta och relevanta meta-tags för att hjälpa till med indexeringen av sidor.
