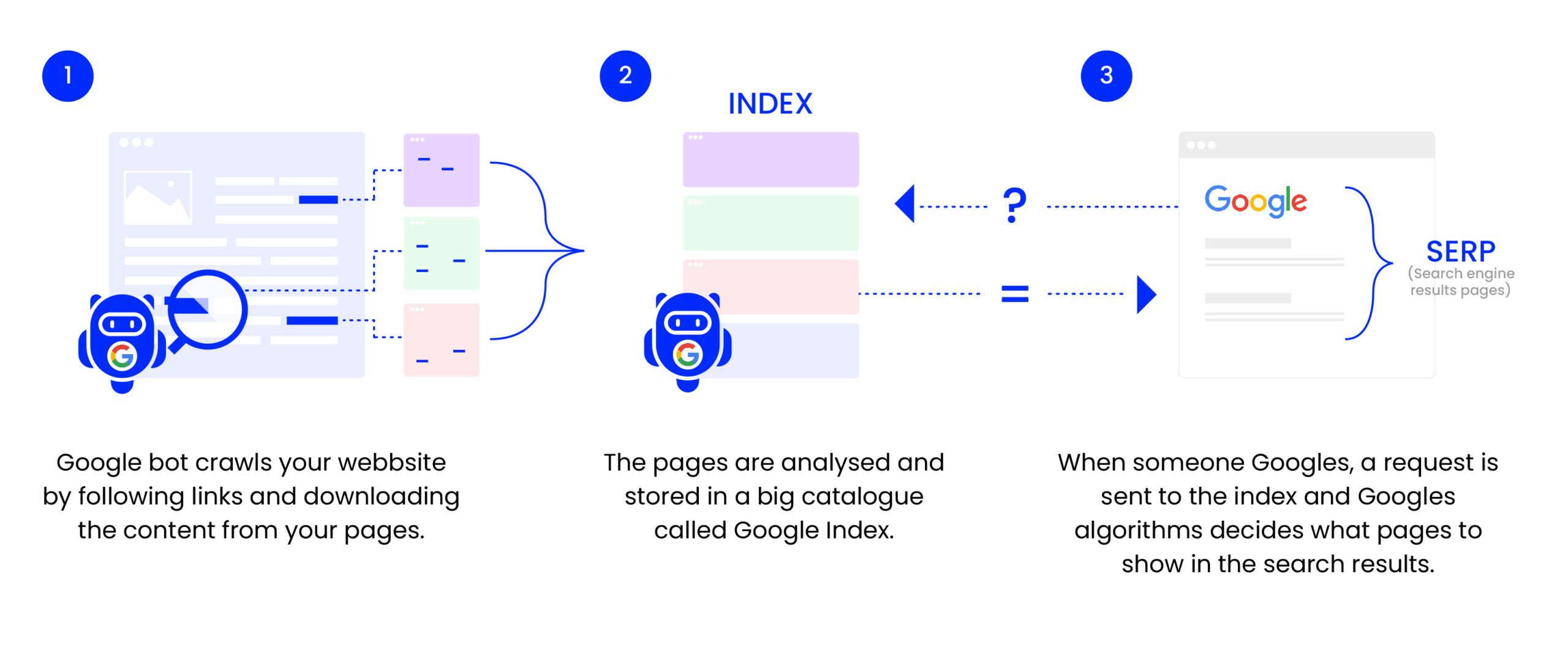
Googlebot är en så kallad webbcrawler, som används av Google för att indexera webbsidor och uppdatera dess sökindex.
För att förstå Googlebot måste man ha grundläggande kunskaper om hur sökmotorer fungerar. Sökmotorer som Google använder ett stort antal datorer för att crawla igenom miljarder sidor på webben. Denna process görs av Googlebot, Googles officiella webbcrawler. Dess uppgift är att besöka nya och uppdaterade webbplatser och att rapportera tillbaka informationen till Google, där den sedan indexeras.
Indexering och dess påverkan på SEO
När Googlebot besöker en webbsida, analyserar den sidans innehåll, struktur och länkar. Informationen som samlas hjälper Google att förstå vad sidan handlar om och hur relevant den är för vissa sökfrågor. Indexering är processen där denna information läggs in i Googles stora databas, eller index. En sida som har indexerats har möjligheten att visas upp i sökresultaten när någon gör en relaterad sökning.
Läs mer om SEO i vår Guide här
Googlebots crawlingprocess
Googlebot startar på kända webbplatser och följer länkar på dessa sidor för att upptäcka nya sidor. Genom en sofistikerad algoritm prioriterar Googlebot vilka sidor som ska besökas först, och hur ofta den ska återvända för att leta efter uppdateringar. Sidornas relevans, uppdateringsfrekvens och andra faktorer spelar in i dessa algoritmer.
Optimera för Googlebot
Att optimera sin webbsida för att göra den tillgänglig och lättförståelig för Googlebot är en grundläggande del av SEO-arbetet. Detta inkluderar:
- Felfri kod: Att se till att webbsidans HTML-kod är korrekt och följer webbstandarder så att Googlebot enkelt kan tolka innehållet.
- Responsiv design: Anpassa webbplatsen för olika enheter och upplösningar för att Googlebot ska förstå att sidan är mobilvänlig.
- Sökbart innehåll: Använd text istället för bilder för att visa innehåll och sökord, eftersom Googlebot lättare kan läsa text.
- Laddningstider: Förbättra snabbheten på sidan eftersom Googlebot och användare föredrar webbplatser som laddar snabbt.
Robot.txt-filer och meta-taggningar
En robot.txt-fil används för att styra accessen för Googlebot. Genom att inkludera eller exkludera delar av en webbplats kan man styra vad som ska crawlas och indexeras. Meta-taggningar såsom ”noindex” och ”nofollow” direkt i HTML-koden kan användas för att tala om för Googlebot att inte indexera en viss sida, eller inte följa länkar på en sida.
Google Search Console och Googlebot
För att hjälpa webbplatsägare att förstå hur Googlebot ser deras sidor, tillhandahåller Google verktyget Google Search Console. Genom denna tjänst kan webbplatsägare se information om indexering, sända in sitemaps för att underlätta krypningen och även begära omindexering av sidor.
Uppdateringar och anpassningar
Googlebot är ständigt under utveckling, då Googles algoritmer är dynamiska och uppdateras regelbundet. Detta betyder att strategier och tekniker för att optimeras för Googlebot även måste uppdateras och anpassas. En SEO-specialist måste hålla sig uppdaterad med Googles förändringar för att kunna ge råd och implementera bästa praxis.
Utmaningar med Googlebot
Trots dess sofistikerade natur kan Googlebot fortfarande stöta på utmaningar när det kommer till att korrekt indexera webbinnehåll. Dynamiskt innehåll genererat av JavaScript och komplexa webside-arkitekturer kan ibland orsaka problem för Googlebots krypnings- och indexeringseffektivitet.
Googlebot spelar en avgörande roll i hur webbinnehåll blir upptäckt och rankat i Googles sökresultat. För effektiv SEO är det fundamentalt att förstå och optimera för Googlebots beteenden. Att ha en webbplats som är optimalt strukturerad och innehållsrik rekommenderas inte bara för användarupplevelsen, utan även för att göra det enkelt för Googlebot att analysera och indexera innehållet.
